Three Modules of FLIP
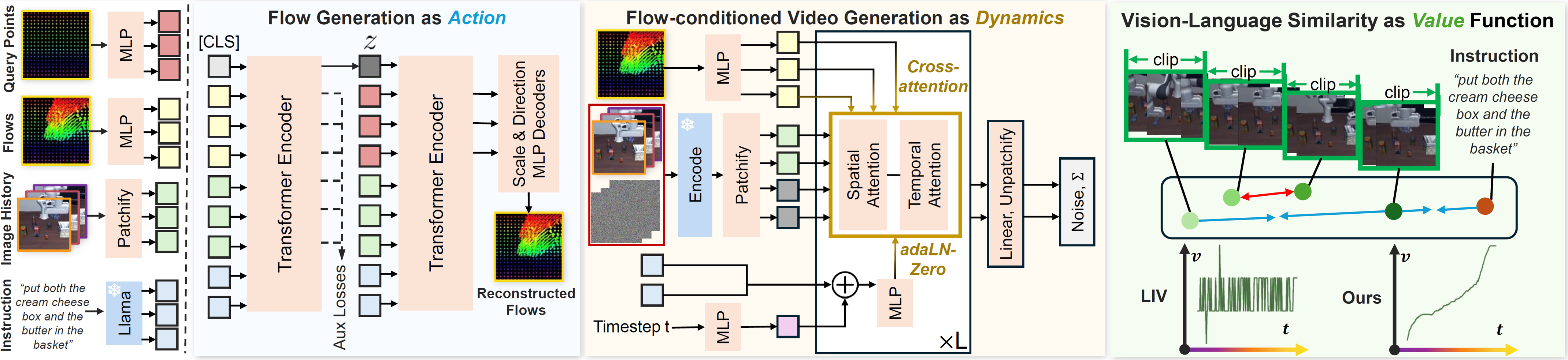
Middle Left: we use a Conditional VAE to generate flows as actions. It separately generates the delta scale and directions on each query point for flow reconstruction.
Middle Right: we use a DiT model with the spatial-temporal attention mechanism for flow-conditioned video generation. Flows (and observation history) are conditioned with cross attention, while languages and timestep are conditioned with AdaLN-zero.
Right: The value module of FLIP. We follow the idea of LIV and use time-contrastive learning for the visual-language representation, but we treat each video clip (rather than each frame) as a state. The fine-tuned value curves of LIV and ours are shown at bottom.